

status
type
date
slug
summary
tags
category
icon
password

maximize 这个objective
开始介绍GRPO这个概念 我们首先回到deepseek math这篇论文
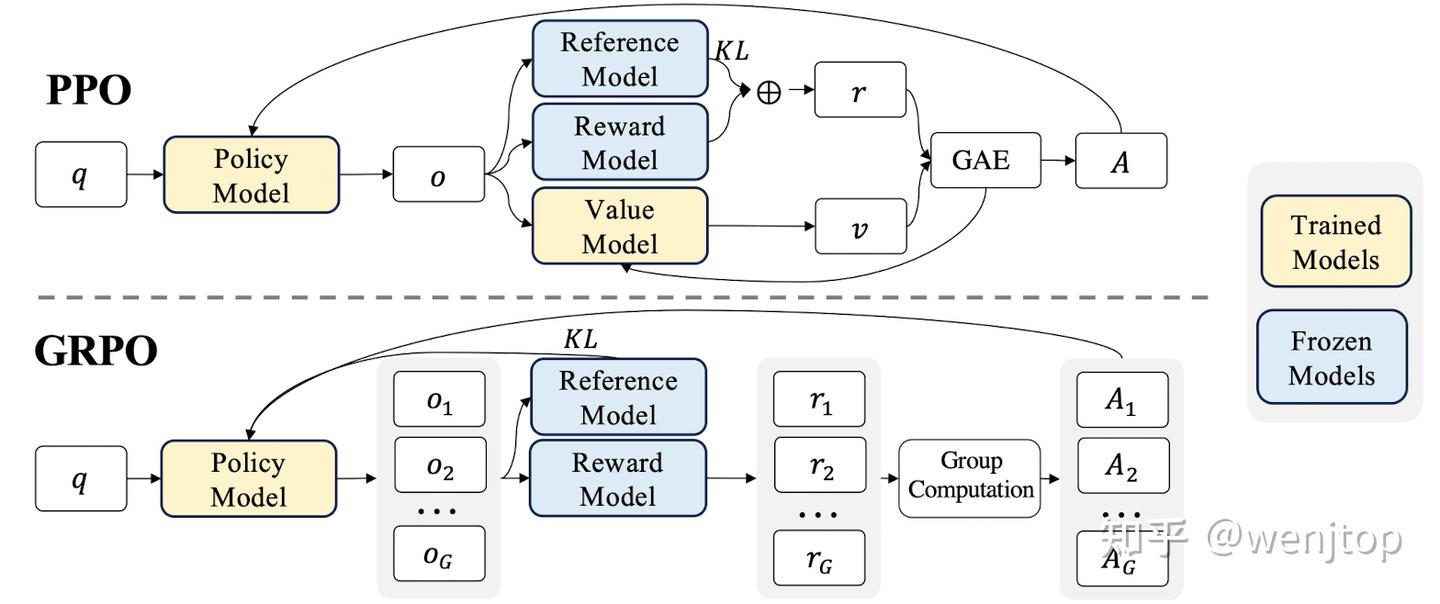
首先我们来看PPO
openai in 2017 (collect batch of feedback based on current policy and update policy, collect brand new batch…)
Each step not too much change → less variance + some bias
→ smoother training 并且确保稳定性
采用这个叫 Actor-Critic approach 也就是上图的policy 和 value model
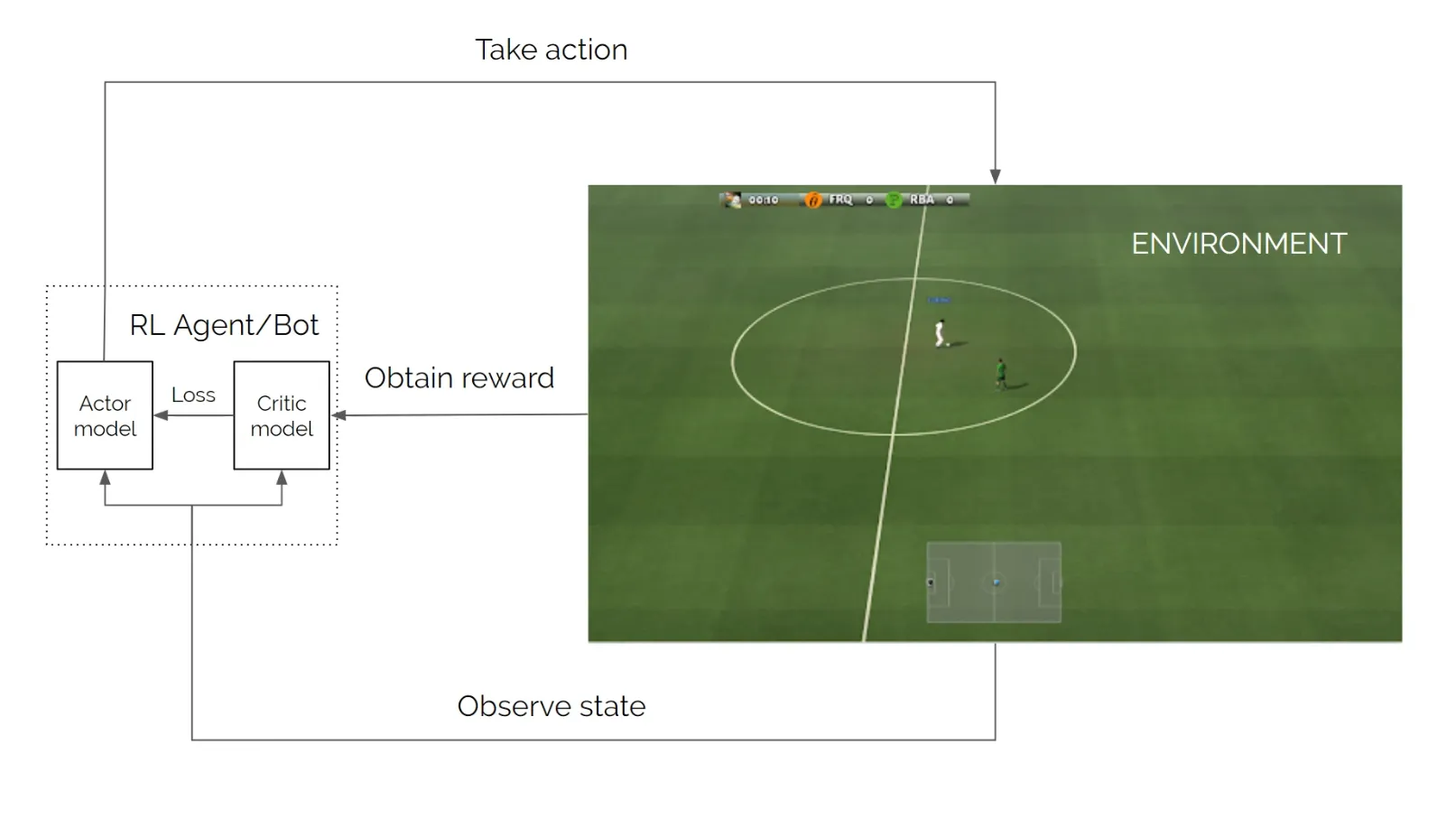
这个案例中用的是google football 做测试
那么我们就用 当前state的rgb 做input → 通过classification model →
当前可以行动的softmax
ok 我们如果采取行动 取得了reward 那么Critic model会告诉我们
我们每一个output的rating 也可以说是value 所以说它对当前形势需要有很强预测/判断能力
通过对新旧两个 value distribution(分别由旧policy和新policy model产出) 作比较
下面这张图很重要 包含了我们后面计算所需要的所有参数
尤其是我们的 value v(s)
注意 action_dist = actor.perdict([curr_state]) 也就是 π(curr_state) 下一步行动dist是我们policy直接产出
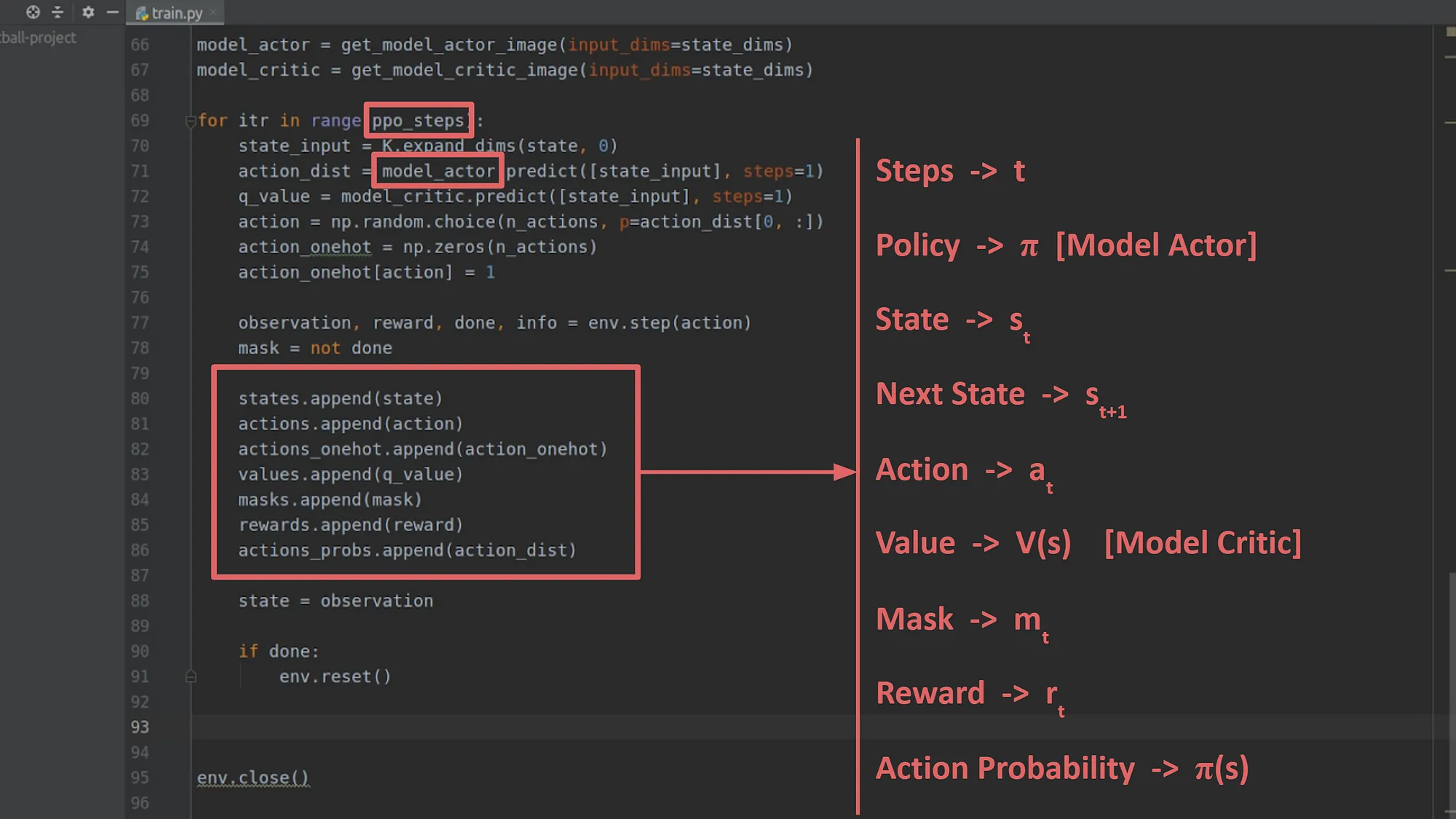
这里我们一共需要记录的值
states + actions + values(当前) + rewards + action_probs(π(state_t) )
就算我们能得知下一步reward 怎么得到具体advantage 因为下一步不见得直接有reward
所以我们需要通过 advantage func计算
Generalized Advantage Estimation (GAE)

先忽略一些parameter
Here, a mask valuemis used because if the game is over then the next state in our batch will be from a newly restarted game so we do not want to consider that and therefore mask value is taken as 0.
Gammaγis nothing but a constant known as discount factor in order to reduce the value of the future state since we want to emphasize more on the current state than a future state. Consider this as scoring a goal in present is more valuable than scoring a goal in future, hence we discount future goal so that we can put more value to a present goal.
Lambdaλis a smoothing parameter used for reducing the variance in training which makes it more stable. The value of this smoothing parameter suggested in the paper is 0.95. Hence, this gives us the advantage of taking an action both in the short term and in the long term.
我们基本可以拆分成两部分 Reward + Critic
Reward 就是直接这一步可以得到的reward
而critic则是分析当前state_t 和 state_t+1的差值 得到 future value
那么这个就是GAE计算方式 我们重新看这张图
我们来到计算PPO环节


PPO 训练策略:
Rollout Phase + Learning Phase
创建N个初始env 放入一个batch中 对其中每一个 同时进行总数为M次step来迭代
next_obs = envs.reset() → 初始env batch
next_done = 初始[0] * n 来记录此env有没有在这个step终结 现在是第一个step 当然都是没有终结的
next_done tells if next_obs is actually the first observation of a new episode对于每个step 进行以下操作
obs = next_obs
done = next_done (这里next done的意思是上一步此env有没有终结 会最终记录在这个step中
如果i_th env 终结了的话 那么这里是nextdone[i] == 1, i_th env初始化回到initial obs in the new episode)
action = agent.get_actijon(obs) 对上一步step完后的env get action
(next_obs, reward, next_done) = envs.step(action)
然后我们记录 data.append([obs, done, action, reward, …])
PPO estimate VALUE for next_obs given next_done && calculate ADVANTAGE
“fixed-length trajectory segments”
总结:
这方面 RLHF 做研究的人太多了 网上写的非常好的材料也很多
参考:
- Author:ran2323
- URL:https://www.blueif.me//article/1a571a79-6e22-80a0-891b-fd9313dca369
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!




